
Built on OmniVoice, the most capable open-source text-to-speech model released to date. This page explains what OmniVoice is, what it can do, and what AethonVoice adds on top.
Published in April 2026 by the k2-fsa research group as a fully open-source project — model weights, training code, and inference pipeline are all publicly available.
OmniVoice sets new benchmarks across every major TTS metric, outperforming commercial systems on multilingual tasks.
| Metric | Score | What It Measures |
|---|---|---|
| 1.30% WER | LibriSpeech-PC (English) | Word Error Rate — how accurately generated speech reproduces input text |
| 0.84% CER | Seed-TTS (Chinese) | Character Error Rate — intelligibility on Chinese text |
| 0.729 SIM-o | LibriSpeech-PC | Speaker Similarity — how closely the voice matches the reference speaker |
| RTF 0.032 | 16-step inference | Real-Time Factor — 1 second of audio in 32ms (30x real-time) |
| 646 languages | Training coverage | Languages represented in training data |
| 82 languages | CER ≤ 5% | Languages with verified high-quality output |
| ~3.0 GB | Model size (fp16) | Compact enough for fast cold starts on GPU |

For context: ElevenLabs and MiniMax are the closest commercial competitors on multilingual benchmarks. OmniVoice matches or exceeds both while being fully open-source.
OmniVoice introduces a diffusion language model-style discrete non-autoregressive (NAR) architecture with several innovations:
Skips the intermediate semantic token stage. Maps text directly to multi-codebook acoustic tokens, eliminating quality loss from two-stage pipelines.
Tokens masked across all 8 codebooks simultaneously, yielding 50% of tokens for loss computation — dramatically more efficient than per-layer masking.
Backbone initialized from Qwen3-0.6B pre-trained weights. The first NAR TTS model to leverage LLM pre-training for superior text understanding.
Extracts 8-codebook acoustic tokens and reconstructs high-fidelity audio, providing the representation layer between text and sound.
OmniVoice was trained on multilingual audio curated from open-source datasets. This is the broadest language coverage of any TTS model to date. Multilingual capability is not bolted on — it is foundational to the architecture.
OmniVoice is a powerful model, but a model is not a product. AethonVoice adds the production-grade features that turn raw TTS capability into a usable service.
| Capability | OmniVoice Alone | AethonVoice |
|---|---|---|
| Generate speech from text | Yes (one language at a time) | Yes, with multilingual mixing in one utterance |
| Voice cloning | Yes (manual reference setup) | Yes, via dashboard — upload audio, get cloned voice |
| Mixed-language text | No — must split manually | Automatic language detection and splitting |
| Paralinguistic expression | No | Pause, laughter, sighs, hesitations via inline tags |
| Long-form audio | No — limited to short segments | Up to 1 hour continuous audio per submission |
| Batch processing | No | Submit hundreds of items, track per-item progress |
| API access | No — Python code only | REST API with async job pattern |
| MCP Server | No | AI assistants can generate speech directly |
| Post-processing | No — raw model output | VAD trimming, crossfade, silence normalization |
When you submit text to AethonVoice, here is what happens.
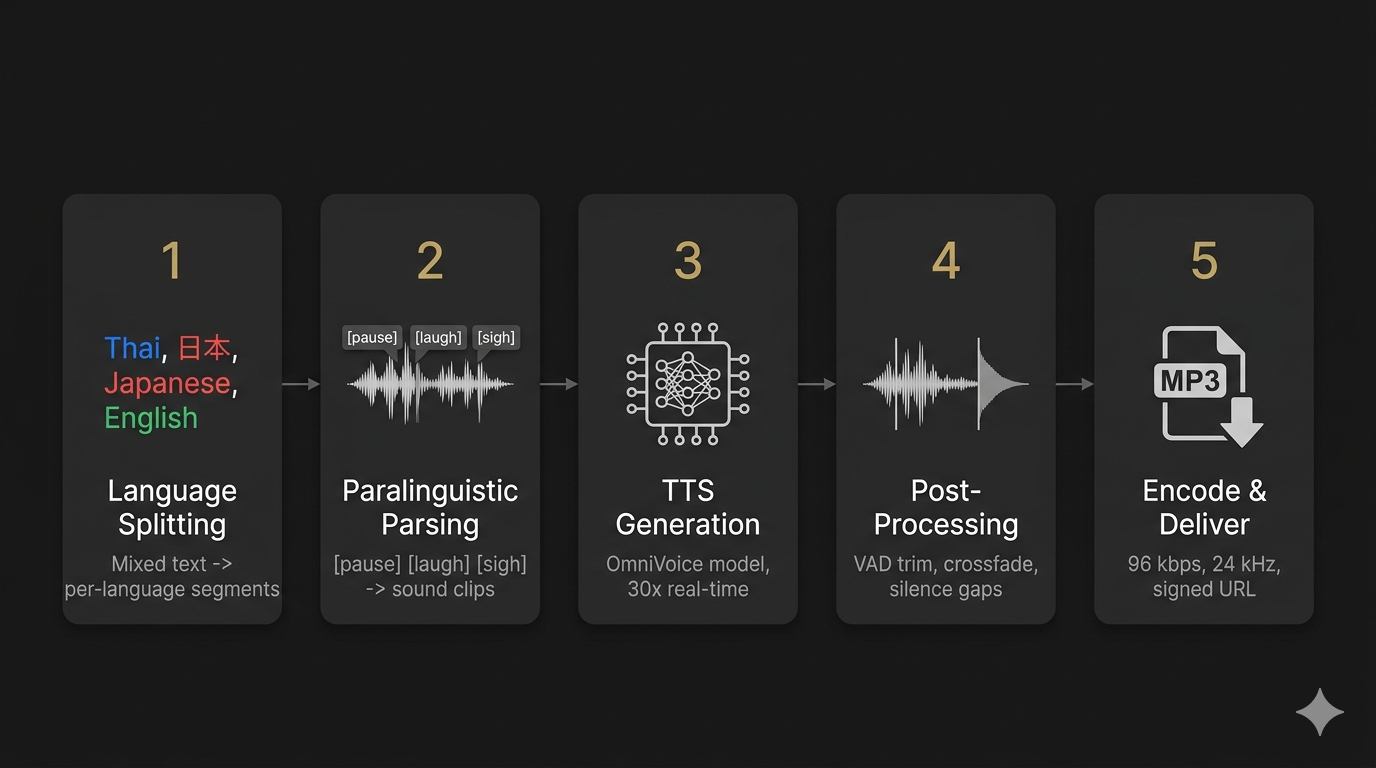
Mixed-language text is split into per-language segments. Explicit tags (<ja>...</ja>) are extracted first. Remaining text is split by Unicode character ranges. Ambiguous boundaries are resolved by a lightweight LLM call.
Inline tags like [pause], [laugh], [sigh], and [er] are extracted. Speech portions go to the TTS model. Tags are replaced with pre-recorded clips from the voice's sound bank.
Each segment is generated using OmniVoice with a language-appropriate voice clone prompt. The same voice identity is maintained across language switches. Generation runs on GPU at 30x real-time speed.
VAD trim removes silence. 40ms fade at boundaries prevents clicks. Crossfade blends clips using equal-power curves (50–120ms randomized). 100ms gaps between language segments for natural pacing.
Final audio encoded to MP3 (96 kbps, 24 kHz, mono) and uploaded to cloud storage. A signed download URL is returned, valid for 7 days.
AethonVoice's open-source foundation is not a marketing angle — it has direct, practical consequences.
The model weights are public. If AethonVoice disappeared tomorrow, the underlying technology would still exist. Compare this to ElevenLabs or OpenAI, where the model is proprietary and inaccessible.
Every benchmark number on this page links to a published paper and reproducible evaluation. You do not have to take our word for it.
Cloud TTS providers charge premium rates because their model is proprietary. AethonVoice pays only for GPU compute — the model is free. This is why we offer $0.015/min instead of $0.03–0.12.
OmniVoice is actively developed by the open-source community. As the model improves, AethonVoice improves — without waiting for a vendor to ship updates.
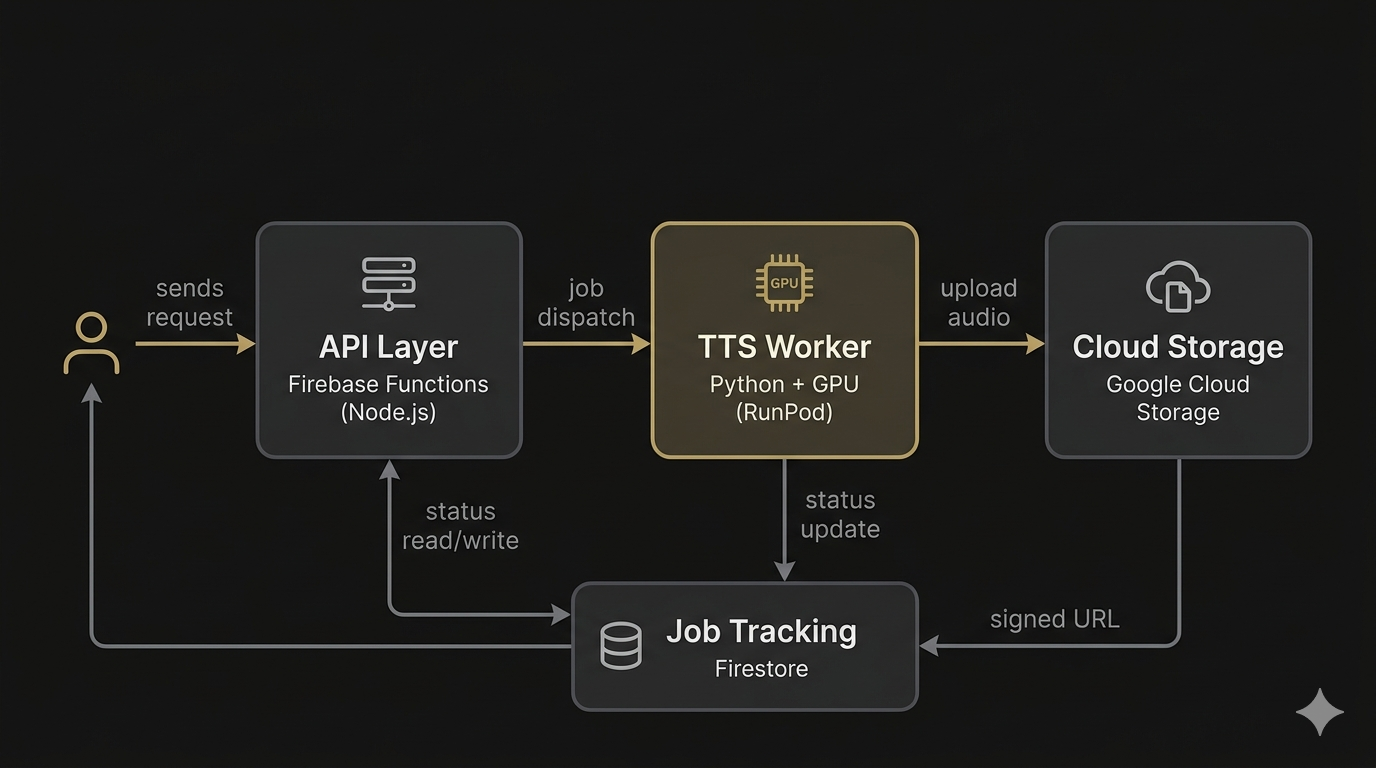
| Layer | Technology | Purpose |
|---|---|---|
| API | Firebase Functions (Node.js) | HTTP endpoints, language splitting, job management |
| TTS Worker | Python + GPU (RunPod) | OmniVoice inference, post-processing, encoding |
| Storage | Google Cloud Storage | Generated audio files (signed URLs, 7-day TTL) |
| Job Tracking | Firestore | Job status, metadata |
The API layer and TTS worker are decoupled. The API handles text processing and job orchestration. The GPU worker handles only TTS generation. This separation allows independent scaling — adding GPU capacity does not require changing the API layer.
Explore the full feature set or learn how to integrate AethonVoice into your workflow.