Everything AethonVoice can do — from voice quality to batch processing to AI assistant integration.
AethonVoice generates speech that is indistinguishable from human voice recordings in most contexts.
Quality is consistent across all 21 supported languages. There is no "tier 1 vs. tier 2" language split — Thai, Japanese, German, and Arabic all receive the same model attention and dedicated voice reference audio.
Each with a defined personality and dedicated reference recordings for all 21 supported languages.

| Voice | Gender | Personality | Best For |
|---|---|---|---|
| Aris | Male | Warm, steady, authoritative. A deep, grounded tone that conveys trust and expertise. | Narration, instruction, educational content, non-fiction audiobooks |
| Nolan | Male | Clear, friendly, upbeat. Approachable with natural energy — like a colleague explaining something over coffee. | Dialogue, conversation, customer-facing content, podcasts, chatbot voices |
| Lyra | Female | Gentle, expressive, emotionally nuanced. A voice that draws the listener in. | Storytelling, fiction audiobooks, emotional content, children's content, meditation |
| Senna | Female | Calm, articulate, professional. Polished and confident without being cold. | Corporate content, e-learning, presentations, professional narration, accessibility |
Each voice maintains its personality and timbre across languages. Aris speaking Thai sounds like the same person as Aris speaking Japanese — the voice identity carries over while pronunciation and prosody adapt naturally.
The underlying OmniVoice model supports zero-shot voice cloning from a short audio sample (as little as 10–15 seconds). No fine-tuning, no training, no waiting.
Upload a reference audio clip via the API.
AethonVoice reproduces the speaker's vocal characteristics.
The cloned voice works across all 21 supported languages.
Cloned voices are stored in your account — use, manage, and delete at any time.
The 4 built-in voices (Aris, Nolan, Lyra, Senna) are available now and use this same zero-shot cloning technology internally, with dedicated per-language reference recordings for consistent quality.
Handle mixed-language text natively — multiple languages in a single sentence, spoken by one voice, with seamless transitions.
ฟังดีๆ นะ คำว่า <ja>コーヒー</ja> แปลว่า coffee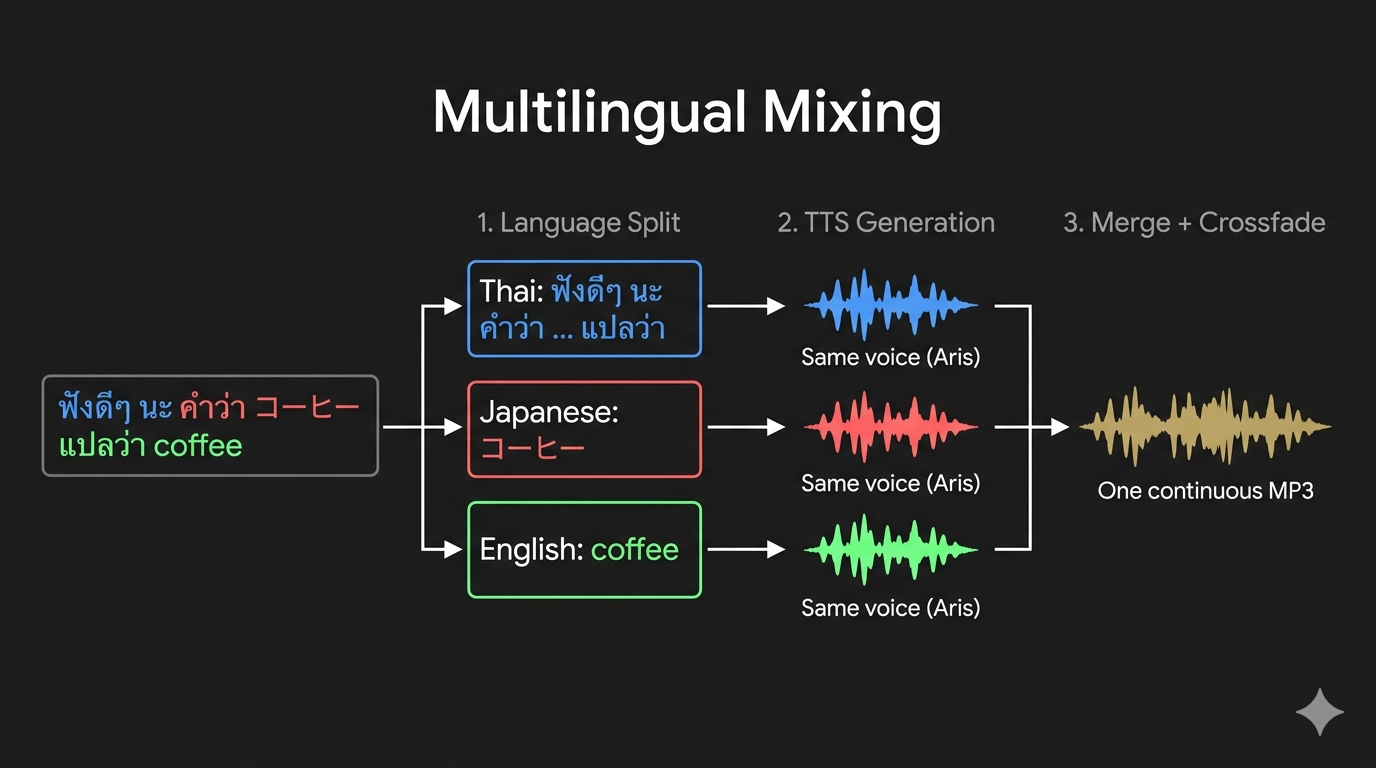
Detects boundaries automatically using Unicode character ranges — Thai script, Japanese kana, Korean hangul, CJK ideographs, Cyrillic, Arabic, Devanagari, Latin, and more. No tags needed.
For ambiguous pairs (e.g., Chinese and Japanese share CJK characters), wrap the target language in tags: <ja>テキスト</ja>. Tagged portions use the specified language.
Ambiguous digits and orphan segments are resolved by a lightweight LLM call. Adds ~1–2 seconds but only triggers when genuine ambiguity exists. Most text splits instantly.
Real speech includes pauses, laughter, hesitation, and sighs. AethonVoice supports inline tags that insert these natural sound effects.
| Tag | Effect | Preview |
|---|---|---|
| [pause] | Natural silence between phrases | |
| [laugh] | Natural laughter | |
| [sigh] | Gentle sigh | |
| [er] | Hesitation / filler sound |
So I was thinking [pause] maybe we should [laugh] just go for it
Each voice has its own set of pre-recorded paralinguistic clips. Clips are randomly selected and seamlessly blended into the surrounding speech. The result: audio that sounds like a person speaking naturally, not a machine reading text.
Each locale has dedicated voice clone reference audio for all 4 built-in voices (96 reference pairs total), verified pronunciation quality, and tested language detection.
| Language | Code | Locale(s) | Script Detection |
|---|---|---|---|
| English | en | en-US, en-GB | Latin |
| Thai | th | th-TH | Thai script |
| Japanese | ja | ja-JP | Hiragana/Katakana + CJK |
| Korean | ko | ko-KR | Hangul + CJK |
| Chinese (Mandarin) | zh | zh-CN, zh-TW | CJK |
| Cantonese | yue | yue-HK | CJK |
| French | fr | fr-FR | Latin |
| German | de | de-DE | Latin |
| Spanish | es | es-ES | Latin |
| Italian | it | it-IT | Latin |
| Portuguese | pt | pt-BR, pt-PT | Latin |
| Russian | ru | ru-RU | Cyrillic |
| Vietnamese | vi | vi-VN | Latin (extended) |
| Turkish | tr | tr-TR | Latin |
| Indonesian | id | id-ID | Latin |
| Malay | ms | ms-MY | Latin |
| Hindi | hi | hi-IN | Devanagari |
| Arabic | ar | ar-SA | Arabic script |
| Bengali | bn | bn-IN | Bengali script |
| Persian (Farsi) | fa | fa-IR | Arabic (extended) |
| Urdu | ur | ur-PK | Arabic (extended) |
The underlying OmniVoice model supports 646 languages, with 82 languages achieving CER of 5% or less. AethonVoice curates the 21 above where quality has been verified end-to-end with dedicated reference audio. Additional languages can be added by providing reference audio and running quality checks.
Generate up to 1 hour of continuous audio from a single submission (approximately 60,000 characters per request).
AethonVoice automatically splits long text at sentence and paragraph boundaries, generates each segment with the same voice, and concatenates everything with crossfade to eliminate audible seams. The output is one continuous MP3 file.
Long-form vs. Batch API: Long-form produces one continuous audio file from one long text. The Batch API produces many separate audio files from many separate texts.
Submit hundreds of TTS items in a single request. Each item is tracked independently — start downloading completed items before the full batch finishes.
Submit an array of items, each with its own text, language, and voice
AethonVoice processes items in parallel (configurable concurrency per GPU)
Poll batch status to see per-item progress
Download each item's MP3 as it completes
Each item in a batch can use a different voice and different languages.
An interface that lets any MCP-compatible AI assistant generate speech directly, without writing code.
MCP (Model Context Protocol) is an open standard created by Anthropic that lets AI assistants use external tools. Think of it as USB for AI — any AI agent that supports MCP can plug into any MCP-compatible tool without custom integration code. Supported by Claude Code, Codex, Coworks, Cursor, Windsurf, and other major AI platforms.
Instead of writing API calls, you tell your AI assistant what you want:
"Read this paragraph aloud using the Lyra voice"
"Generate Thai pronunciation for สวัสดีครับ"
"Create an audio version of this blog post"Add audio to their work without touching code.
Generate pronunciation guides effortlessly.
Create audio versions of their text.
Who wants TTS without learning an API.
24 kHz captures 100% of the speech signal (human speech tops out at ~8 kHz, well within the 12 kHz Nyquist limit). 96 kbps achieves perceptual transparency for speech — the compressed audio is indistinguishable from the uncompressed original in listening tests.
For context, OpenAI TTS also outputs at 24 kHz — this reflects the TTS research consensus that 24 kHz is optimal for speech synthesis.
| Parameter | Value |
|---|---|
| Format | MP3 |
| Bitrate | 96 kbps |
| Sample rate | 24 kHz |
| Channels | Mono |
| Download | Signed URL (7-day expiry) |
AethonVoice is the only service that combines multilingual mixing, paralinguistic expression, and an open-source model foundation.
| Feature | AethonVoice | ElevenLabs | Google TTS | Amazon Polly | Azure TTS | OpenAI TTS | PlayHT | Cartesia |
|---|---|---|---|---|---|---|---|---|
| Voice quality | Excellent | Excellent | Good-Excellent | Good | Good | Good | Good | Good |
| Zero-shot cloning | Yes (instant) | Yes (instant + pro) | No | No | No | No | Yes | Yes |
| Languages | 21 curated (646 model) | 32+ | 40+ | 30+ | 100+ | ~57 | 142+ | 10+ |
| Multilingual mixing | Yes (auto split + merge) | Limited | No | No | No | No | No | No |
| Paralinguistic tags | Yes (pause, laugh, sigh, er) | No | Limited (SSML) | Limited (SSML) | SSML-based | No | No | No |
| Streaming | Planned | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Batch API | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes |
| Long-form (1hr+) | Yes | Yes | No (5000 char) | Yes | Yes | 4096 char limit | Yes | Yes |
| Open-source model | Yes (OmniVoice) | No | No | No | No | No | No | No |
| Credit expiration | Never | Monthly reset | Pay-per-use | Pay-per-use | Pay-per-use | Pay-per-use | Monthly reset | Monthly reset |
WebSocket endpoint for real-time audio streaming. Target: first audio byte in under 500ms. Enables voice agents, chatbots, and real-time translation.
LLM pre-processing that automatically inserts paralinguistic tags. Submit plain text; AethonVoice adds the expressiveness. Configurable: minimal, natural, dramatic.
WAV, OGG, FLAC support. Configurable bitrate (64–320 kbps) and sample rate (16–48 kHz).
Remove the need to specify expected languages. AethonVoice will detect languages present in the text automatically.
Python (pip install aethonvoice) and Node.js/TypeScript (npm install aethonvoice) client libraries.
Hear these features in action, see what it costs, or start building today.