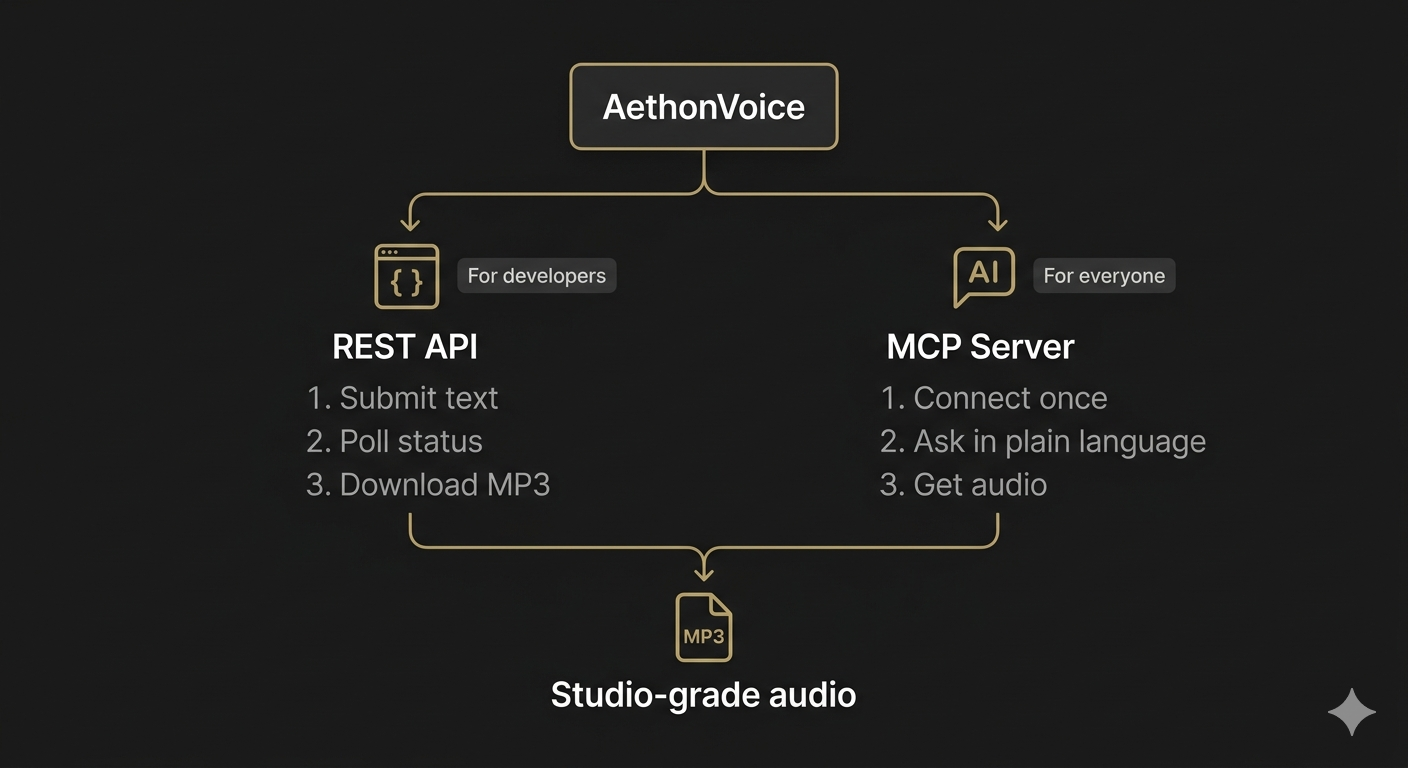
Two ways to use AethonVoice. Pick the one that fits.
Two ways to get results: poll for status, or let us call your webhook when it's ready. Two modes to submit: single job via POST /tts/submit, or batch via POST /tts/batch-submit for many items in one request — see Batch Processing below.
Submit a job, check back periodically, download when ready. Simple and reliable.
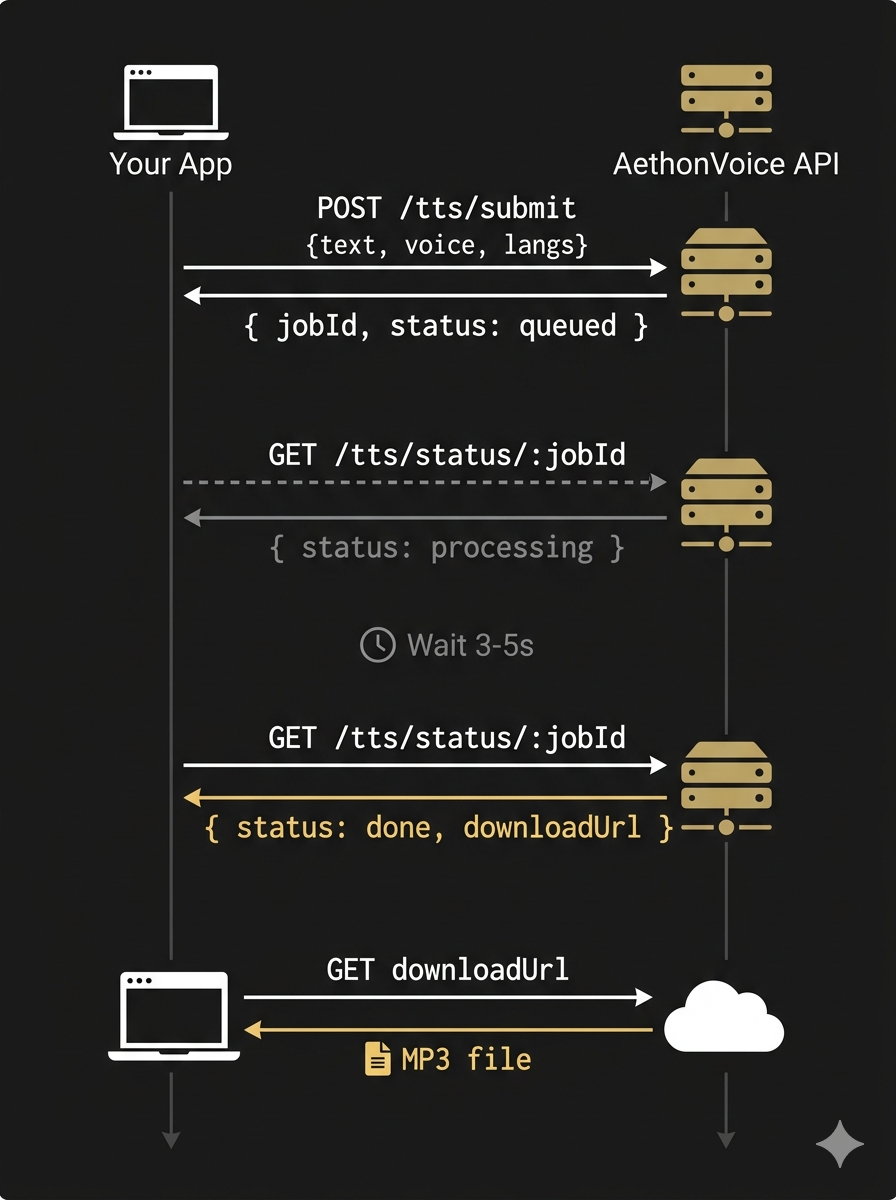
1. POST /tts/submit → { jobId, status: "queued" }
2. GET /tts/status/:jobId → { status: "processing" }
3. GET /tts/status/:jobId → { status: "done", downloadUrl: "..." }
4. Download MP3 from downloadUrl (no auth needed)Provide a callbackUrl and we'll POST the results to your server when the job completes. No polling needed.
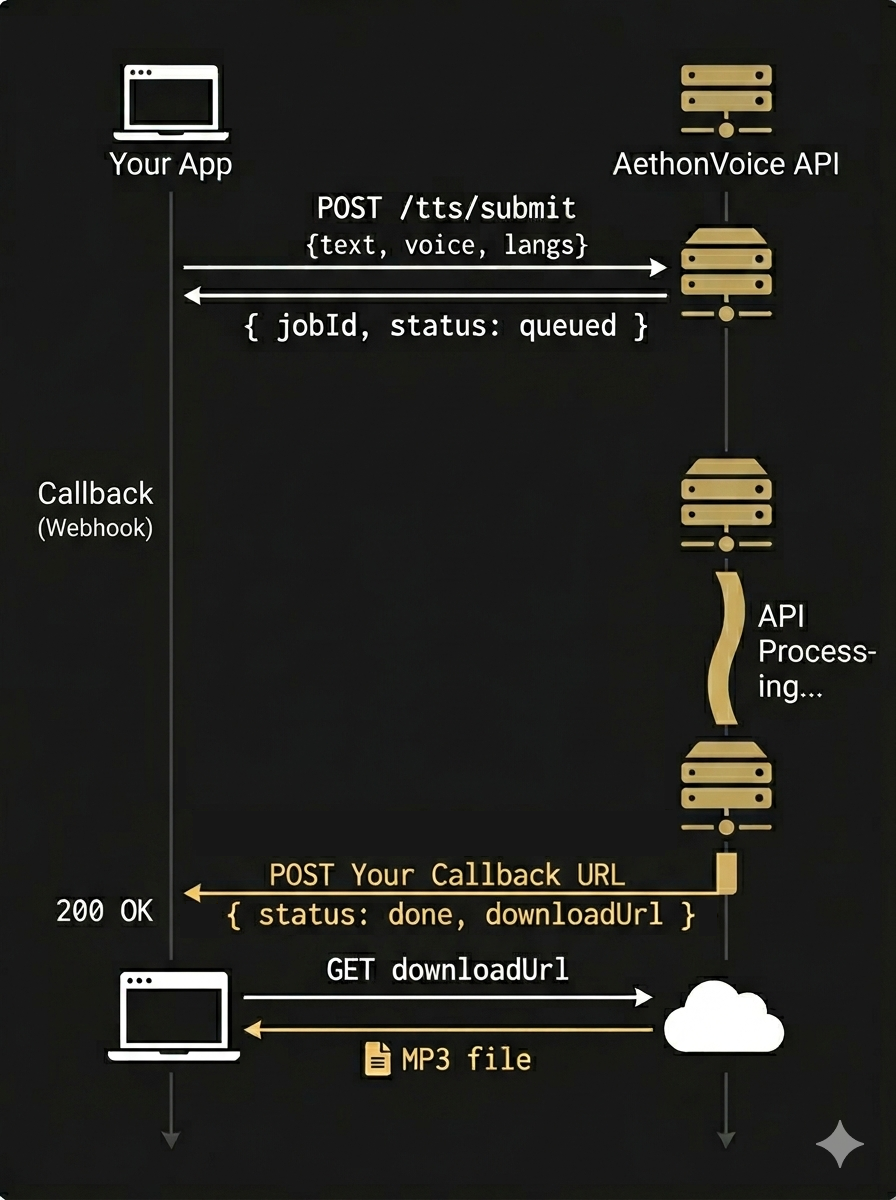
1. POST /tts/submit → { jobId, status: "queued" }
body: { text, voice, langs, callbackUrl: "https://your-server.com/webhook" }
2. (your app does other work — no polling needed)
3. POST your callbackUrl ← AethonVoice calls you
{
"jobId": "Xk9mP2qR7vNw",
"status": "done",
"downloadUrl": "https://storage.googleapis.com/...",
"durationMs": 2100
}
4. Download MP3 from downloadUrl (no auth needed)Best for batch jobs and server-to-server integrations. You can still poll GET /tts/status/:jobId as a fallback.
If generation fails, you still receive a callback — the payload carries a top-level error string so you don't have to walk the items map:
{
"batchId": "Bt9xK2pL...",
"status": "error",
"error": "All 3 items failed",
"items": { /* per-item status + error */ }
}Credits are only debited for items that successfully returned audio — failed items are never charged.
Sign up and create an API key from your dashboard. Keys are issued in the form av_live_<32-bytes-base64url> and shown only once at creation — we store a SHA-256 hash, never the raw key. Send it as Authorization: Bearer <key> on every request (the X-API-Key header is also accepted).
curl -X POST https://aethon.lab.ai/api/tts/submit \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"text": "Welcome to AethonVoice.",
"voice": "aris",
"langs": ["en"]
}'Response:
{
"jobId": "Xk9mP2qR7vNw",
"status": "queued"
}curl https://aethon.lab.ai/api/tts/status/Xk9mP2qR7vNw \
-H "Authorization: Bearer YOUR_API_KEY"Response (when complete):
{
"jobId": "Xk9mP2qR7vNw",
"status": "done",
"downloadUrl": "https://storage.googleapis.com/...",
"durationMs": 2100
}The downloadUrl is a signed URL. Download it directly — no authentication header needed.
| Endpoint | Method | Description |
|---|---|---|
/tts/submit |
POST | Submit single TTS job |
/tts/batch-submit |
POST | Submit batch of TTS items |
/tts/status/:jobId |
GET | Poll single job status |
/tts/batch-status/:batchId |
GET | Poll batch status with per-item progress |
| Status | Meaning |
|---|---|
queued |
Job received, waiting for GPU worker |
processing |
Audio is being generated |
done |
Audio ready — downloadUrl included |
error |
Generation failed — error message included |
partial |
(Batch only) Some items succeeded, some failed |
1 credit = 1 second of generated audio, rounded up per job. Charges are always based on the actual duration returned — never on your input text length — and failed items are never debited.
Before we queue a job, we run a quick pre-flight estimate based on character count and language speaking rate. If the estimate exceeds your available balance by more than a 30-second tolerance, the request is rejected with 402 Payment Required before any work is done:
{
"error": "Insufficient credits",
"estimatedSec": 420,
"balance": 85
}A 30-second tolerance means borderline jobs are allowed through and may end the session with a small negative balance — the next top-up restores you automatically.
| Code | Meaning | When |
|---|---|---|
400 |
Bad Request | Missing/invalid text, voice, or langs |
401 |
Unauthorized | Missing Authorization header, or key invalid/revoked |
402 |
Payment Required | Estimated duration exceeds balance + 30s tolerance |
404 |
Not Found | Unknown jobId or batchId |
429 |
Rate Limited | Too many requests in the current window |
Submit multiple items in one request. Each item can have different text, voice, and languages — useful for dubbing, dataset generation, or multi-speaker scripts.
curl -X POST https://aethon.lab.ai/api/tts/batch-submit \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"items": [
{ "key": "word-01", "text": "สวัสดีครับ", "voice": "aris", "langs": ["th"] },
{ "key": "word-02", "text": "こんにちは", "voice": "lyra", "langs": ["ja"] },
{ "key": "word-03", "text": "Auf Wiedersehen", "voice": "nolan", "langs": ["de"] }
],
"callbackUrl": "https://your-server.com/webhook"
}'Response:
{
"batchId": "Bk8nQ3rS6uMx",
"status": "queued",
"itemCount": 3
}Poll GET /tts/batch-status/:batchId to see per-item progress. Start downloading completed items before the full batch finishes. If you supplied callbackUrl, we POST the final payload to your server — no polling needed.
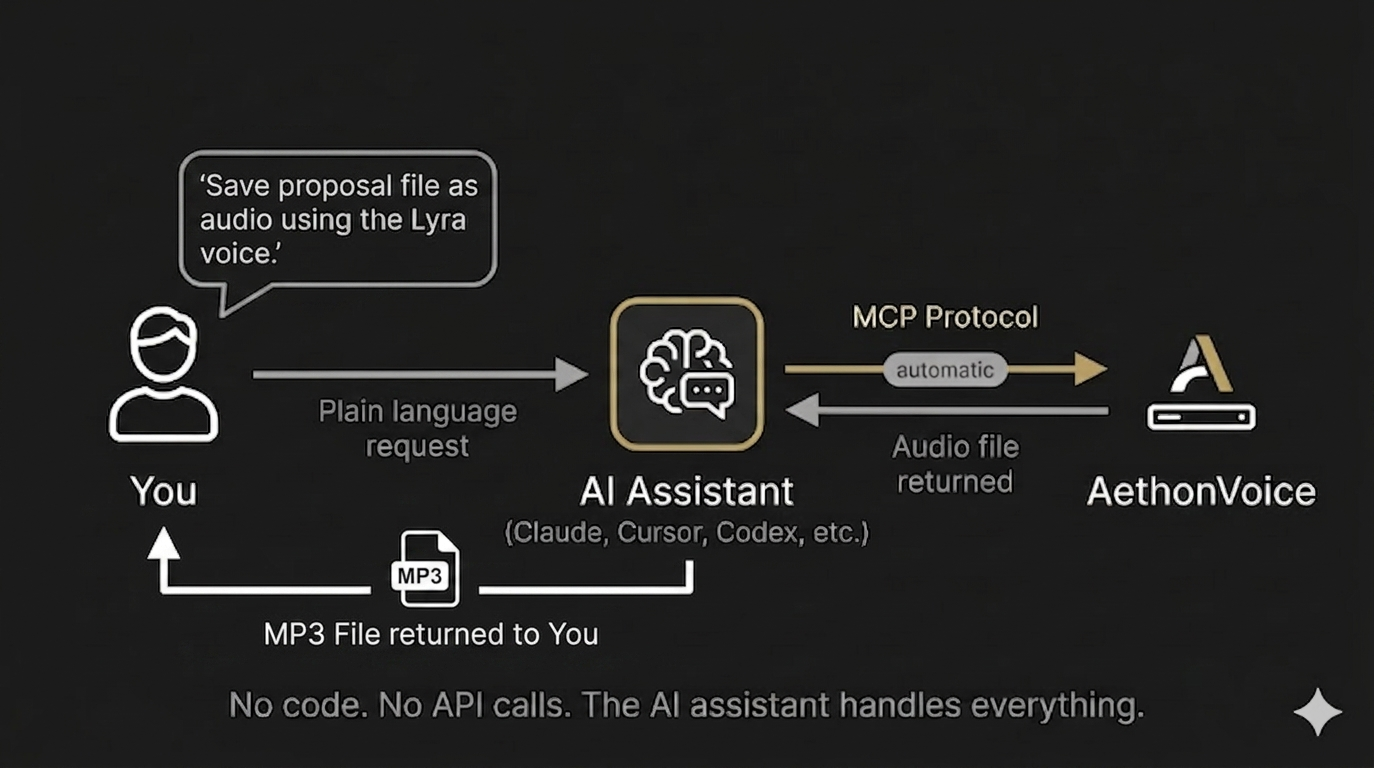
No code required. AethonVoice will work as a tool inside any MCP-compatible AI assistant.
An AI assistant that supports MCP (Claude Code, Codex, Coworks, Cursor, Windsurf, and others)
An AethonVoice API key
A one-time MCP Server connection setup
Once connected, you talk to your AI assistant in plain language:
"Generate Thai pronunciation for สวัสดีครับ using the Aris voice"
The assistant calls AethonVoice, generates the audio, and returns a download link.
"Read this paragraph aloud with the Lyra voice"
Paste any text. The assistant sends it to AethonVoice and gives you the MP3.
"Create audio for this blog post in French"
Long-form content works too. The assistant handles the submission and polling automatically.
"Pronounce this Japanese word: ありがとうございます"
Quick pronunciation lookups — useful for language learning, content creation, or accessibility.
Plain text in any of the 21 supported languages (24 locale variants). Mixed-language text is handled automatically.
For explicit control over language boundaries, wrap portions in XML-style tags:
<ja>聞いてください</ja> This is English <th>สวัสดีครับ</th>Tags are optional. Tagged portions use the specified language. Untagged portions are split automatically by character range detection. You can mix tagged and untagged text freely.
When to use tags: When languages share the same script (e.g., Chinese and Japanese both use CJK characters). For most other language pairs, automatic detection works without tags.
Insert natural sound effects inline:
| Tag | Effect |
|---|---|
[pause] |
Silence (0.7-1.1s, randomized) |
[laugh] |
Laughter from voice's sound bank |
[sigh] |
Sigh from voice's sound bank |
[er] |
Hesitation / filler sound |
I was thinking [pause] maybe we should [laugh] just go for itTags work with both API and MCP Server.
| Voice | ID | Gender | Character |
|---|---|---|---|
| Aris | aris |
Male | Warm, steady, authoritative |
| Nolan | nolan |
Male | Clear, friendly, upbeat |
| Lyra | lyra |
Female | Gentle, expressive, nuanced |
| Senna | senna |
Female | Calm, articulate, professional |
| Field | Required | Description |
|---|---|---|
callbackRef |
No | Opaque reference string stored with the job. Useful for correlating results with your own records. |
Specify languages with the langs array. The first element is the primary language. List all languages present in your text.
| Code | Language | Code | Language |
|---|---|---|---|
en |
English | id |
Indonesian |
th |
Thai | ms |
Malay |
ja |
Japanese | hi |
Hindi |
ko |
Korean | ar |
Arabic |
zh |
Chinese (Mandarin) | bn |
Bengali |
yue |
Cantonese | fa |
Persian |
fr |
French | ur |
Urdu |
de |
German | vi |
Vietnamese |
es |
Spanish | tr |
Turkish |
it |
Italian | ru |
Russian |
pt |
Portuguese |
| Parameter | Value |
|---|---|
| Format | MP3 |
| Bitrate | 96 kbps |
| Sample rate | 24 kHz |
| Channels | Mono |
| Download URL expiry | 7 days |
These numbers look lower than music streaming, but they're optimal for speech. Human speech tops out at ~8 kHz — well within the 12 kHz Nyquist limit of a 24 kHz sample rate. 100% of the speech signal is captured.
At 96 kbps MP3, the compressed audio is perceptually transparent for speech — indistinguishable from the uncompressed original in listening tests. The result: smaller files, faster downloads, identical quality.
For context, OpenAI TTS also outputs at 24 kHz. This reflects the TTS research consensus that 24 kHz is the sweet spot for speech synthesis. Higher sample rates add file size with zero audible benefit for voice.
Download URLs are signed — no authentication needed to download. The cryptographic signature carries access. URLs cannot be guessed or enumerated.
This page covers the essentials. For complete API reference including all request/response schemas, error codes, rate limits, and advanced usage:
Read the Full API DocsStudio-grade TTS in minutes. Choose your path.
Use AethonVoice through any MCP-compatible AI assistant. No code needed.
Set Up MCP Soon Claude Code, Cursor, Windsurf & more